Architecture¶
Overview¶
The following figure illustrates the architecture of Vineyard.
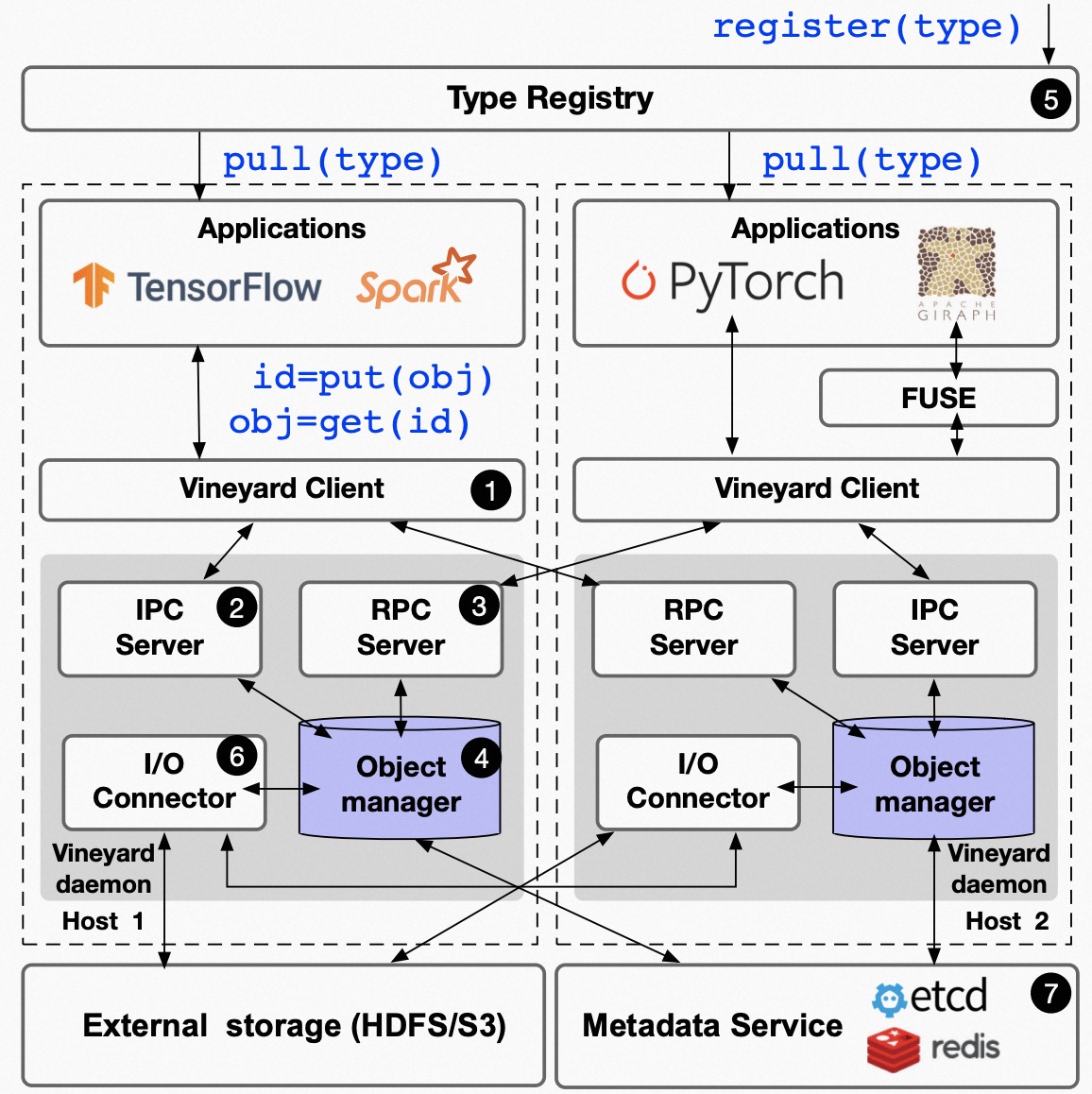
Architecture of Vineyard¶
Server side¶
On the server (daemon) side (i.e., the aforementioned Vineyard instance), there are three primary components:
The shared memory is the memory space in Vineyard that is shared with Vineyard clients via the UNIX domain socket through memory mapping.
As previously mentioned, the partitions of the distributed data reside in the shared memory of the corresponding Vineyard instance in the cluster.
The metadata manager is responsible for managing the metadata of the data stored in Vineyard.
The metadata manager maintains the metadata (structures, layouts, and properties) of the data to provide high-level abstractions (e.g., graphs, tensors, dataframes). The metadata managers in a Vineyard cluster communicate with each other through the backend key-value store, such as etcd server, to ensure the consistency of the distributed data stored in Vineyard.
The IPC/RPC servers manage the IPC/RPC connections from Vineyard clients for data sharing.
Specifically, the client can retrieve both metadata and data partitions stored in Vineyard via IPC and RPC connections. However, when both connection types are available, IPC connections are prioritized due to the greater efficiency of memory mapping for data sharing.
Client side¶
On the client side, the core component is the Vineyard client. The client side includes both low-level APIs for accessing Vineyard instances in a precise manner and high-level APIs for data structure sharing, manipulation, and routine reuse (e.g., I/O drivers). More specifically,
The IPC client communicates with local Vineyard instances by connecting to the UNIX domain socket.
The IPC client is used to establish an IPC connection between the Vineyard server and the client, enabling memory-sharing (by
mmapand transferring the file descriptor) between the Vineyard server and the computing engines.The RPC client communicates with remote Vineyard instances by connecting to the TCP port that the Vineyard daemon is bound to.
Unlike the IPC client, the RPC client doesn’t allow memory sharing between processes and is less efficient in that regard. However, it is still useful for retrieving both metadata and payloads from the Vineyard cluster via TCP or RDMA.
The builders and resolvers for out-of-the-box high-level data abstractions offer a convenient way for applications to consume objects in Vineyard and produce result objects into Vineyard.
The builders and resolvers adopt an extensible design where users can register their own builders and resolvers for their newly defined data types, as well as new builders and resolvers that build ad-hoc engine-specific data structures as Vineyard objects and wrap Vineyard objects as engine-specific data types at a low cost.
The builders, resolvers, and the registry are part of the language-specific SDKs of Vineyard. Currently, Python and C++ are officially supported, and the Rust and Go SDKs are under heavy development.
The pluggable drivers assign specific functionalities to certain types of data in Vineyard.
In particular, I/O drivers synchronize with external storages such as databases and file systems to read data into and write data from Vineyard, while partition and re-partition drivers reorganize the distributed graphs stored in Vineyard to balance the workload.
Note
The drivers typically employ the low-level APIs for precise operations.
Object migration is the mechanism implemented on the client side to migrate objects between Vineyard instances in a cluster. Object migration is usually needed when the computing engines cannot be scheduled to co-locate with the data required by the jobs.
Object migration is implemented on the client side as a process pair where the sender and receiver are both connected to (different) Vineyard instances and communicate with each other using TCP to move objects between Vineyard instances. We don’t put the object migration on the server side to decouple the functionalities and allow users to register a more efficient object migration implemented on their own deployment infrastructures, e.g.,leveraging RDMA and other high-performance network technologies.
Core features¶
Zero-cost in-memory data sharing¶
Vineyard provides zero-cost data sharing through memory-mapping, as data objects in Vineyard are immutable. When an object is created, we allocate blobs in Vineyard to store the data payload. On the other hand, when retrieving the object, we map the blob from the Vineyard instance into the application process using inter-process memory mapping techniques, ensuring that no memory copy is involved in sharing the data payload.
Distributed data sharing in big data tasks¶
By examining the practices of big data tasks such as numeric computing, machine learning, and graph analysis, we have identified four key properties of the data involved:
Distributed and each partitioned fragment usually fits into memory;
Immutable, i.e., never modified after creation;
With complex structure, e.g., graph in CSR format;
Required to share between different computation systems and programming languages.
Vineyard is designed to address these challenges with:
Composable design for Vineyard objects;
Immutable zero-cost in-memory data sharing via memory mapping;
Out-of-the-box high-level data abstraction for complex data structures;
Extensible design for builder/resolver/driver, enabling flexible cross-system and cross-language data sharing.
In general, Vineyard’s design choices are fully determined by addressing the difficulties in handling large-scale distributed data in practice.
Out-of-the-box high-level data abstraction¶
Vineyard objects are stored with structures and high-level abstractions. For instance, a graph with CSR format in Vineyard stores the index along with the vertices and edges, enabling operations like edge iteration based on the index. This means users don’t have to implement the index-building function and edge iterators themselves, which is often required in existing big data practices.
Convenient data integration¶
The extensible design of builder/resolver/driver allows for convenient extension of existing Vineyard objects to different programming languages. Moreover, with codegen tools in Vineyard, users can easily transplant their data structures into Vineyard with only a few annotations.
Data orchestration in a Python notebook¶
Using Vineyard as the common data orchestration engine throughout the end-to-end big data processing, users can hold large-scale distributed data as variables of Vineyard objects in Python. As long as the computation modules involved provide Python APIs, users can write down the entire processing pipeline in a Python notebook. By running the Python script, users can manage trillions of data and different computation systems in the background distributedly across the cluster.
Non-goals and limitations¶
NO mutable objects¶
Once a Vineyard object is created and sealed in the Vineyard instance, it becomes immutable and can NOT be modified anymore. Thus, Vineyard is not suitable for use as a data cache to store mutable data that changes rapidly along the processing pipeline.