Objects¶
Vineyard represents various data types as vineyard objects. It employs a metadata-payloads decoupled design, where an object in vineyard comprises:
A collection of blobs containing the actual data payload;
A hierarchical meta tree that describes the data’s type, layout, and properties.
Object = metadata + payloads¶
There are some examples that explain the basic idea of metadata and payload that forms vineyard objects:
Blob: A blob is a pointer with a length that describes the size of the data,
metadata:
length
payloads:
pointer, the actual payload of the blob
Tensor: A tensor can be viewed as a blob that contains the actual data and several metadata entries that describe the shape and type information,
metadata:
shapedtypedata, a member with typeBlob
payloads:
pointerin the memberdata
Dataframe: A dataframe is an ordered collection of tensors as its columns and each column has a unique name,
metadata:
column_sizenames, a list of members with typestringcolumns, a list of member with typeTensor
payloads:
a set of
pointerin the membercolumns(the memberdataof of thoseTensors)
From the example above, it is evident that objects naturally conform to a hierarchical model, allowing complex data objects to be composed of simpler ones. Each object consists of a set of blobs as the payload and a metadata tree that describes the semantics and organization of those blobs.
An example for the object metadata: a dataframe with two columns where each column is a tensor.
{
"__values_-key-0": "1",
"__values_-key-1": "\"a\"",
"__values_-size": 2,
"__values_-value-0": {
"buffer_": {
"id": "o800527ecdf05cff9",
"instance_id": 39,
"length": 0,
"nbytes": 0,
"transient": true,
"typename": "vineyard::Blob"
},
"id": "o000527ecdffd95c4",
"instance_id": 39,
"nbytes": 400,
"partition_index_": "[]",
"shape_": "[100]",
"signature": 1451273207424436,
"transient": false,
"typename": "vineyard::Tensor<float>",
"value_type_": "float"
},
"__values_-value-1": {
"buffer_": {
"id": "o800527ecdeaf1015",
"instance_id": 39,
"length": 0,
"nbytes": 0,
"transient": true,
"typename": "vineyard::Blob"
},
"id": "o000527ece12e4f0a",
"instance_id": 39,
"nbytes": 800,
"partition_index_": "[]",
"shape_": "[100]",
"signature": 1451273227452968,
"transient": false,
"typename": "vineyard::Tensor<double>",
"value_type_": "double"
},
"columns_": "[\"a\",1]",
"id": "o000527ece15d374c",
"instance_id": 39,
"nbytes": 1200,
"partition_index_column_": 0,
"partition_index_row_": 0,
"row_batch_index_": 0,
"signature": 1451273231074538,
"transient": false,
"typename": "vineyard::DataFrame"
}
From the above example of object metadata, it is evident that an object is composed of various sub-objects, forming a hierarchical data model. Each object consists of a set of blobs and a metadata tree that describes the semantics of those blobs.
Tip
Without the metadata, the set of blobs would merely be a collection of memory pieces without any meaningful interpretation.
Refer to Sharing Python Objects with Vineyard for a demonstration of how to put Python objects into vineyard and retrieve them using IPC clients.
Separating metadata and payload¶
The decoupling of data payload and data layout in vineyard offers three key advantages:
Payloads are stored locally within each vineyard instance, while metadata is shared across all instances in the cluster. This significantly reduces the overhead of maintaining consistency for distributed data.
Vineyard objects become self-descriptive, as the metadata fully determines how the object should be resolved. This not only ensures semantic consistency when sharing vineyard objects between different systems and programming languages, but also allows users to store complex data structures with high-level abstractions, such as graphs in CSR format directly in vineyard, without the need for serialization/deserialization every time the object is saved or loaded.
This design enables the exploitation of data-aware scheduling techniques. For example, when processing a graph in vineyard, we can easily access the metadata tree of the graph to determine the size of each partitioned fragment without accessing the actual vertices and edges. As a result, we can allocate precise amounts of computational resources for each fragment, leading to overall performance improvements.
Vineyard employs two design choices for the metadata and methods of its objects:
A composable design for vineyard objects, which facilitates distributed data management;
An extensible design for object methods, enabling flexible data sharing between different computation systems with minimal additional development cost.
Data model¶
Composable¶
The composition mechanism in vineyard is based on the hierarchical tree structure of the metadata of its objects. The root metadata of a complex object stores references to the root metadata of its components. By recursively traversing these references, a complete metadata tree is constructed for the complex object.
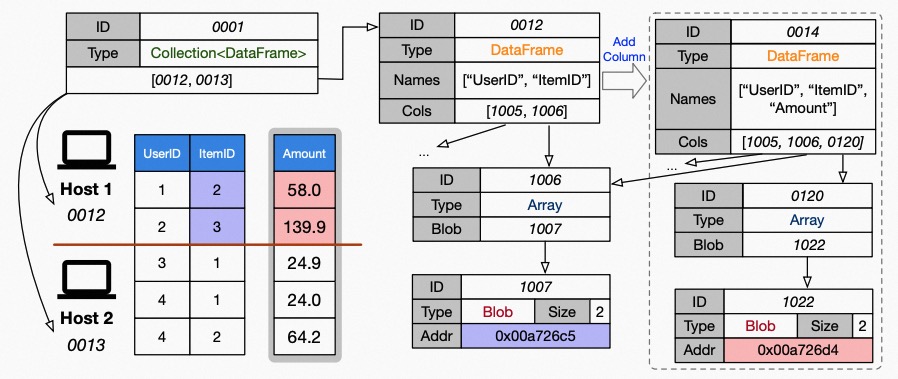
Vineyard objects are composable¶
For instance, a distributed dataframe consists of partitioned dataframe chunks, while a dataframe is composed of column vectors. Considering the decoupling design of payload and layout in vineyard objects, the blobs are stored in the corresponding vineyard instance’s memory for each partition, and the metadata (e.g., chunk index, shape, column data types) are stored in the key-value store behind the metadata service.
To store a distributed graph, we first save the partitioned fragments in each vineyard instance and share their metadata in the backend key-value store. Then, we can create the distributed graph by generating the root metadata containing links to the root metadata of the fragments in an efficient manner.
Distributed objects¶
Vineyard is designed to store large objects across multiple nodes in a cluster, enabling user programs to seamlessly interact with these objects as a single entity. Data is sharded across multiple machines without replication.
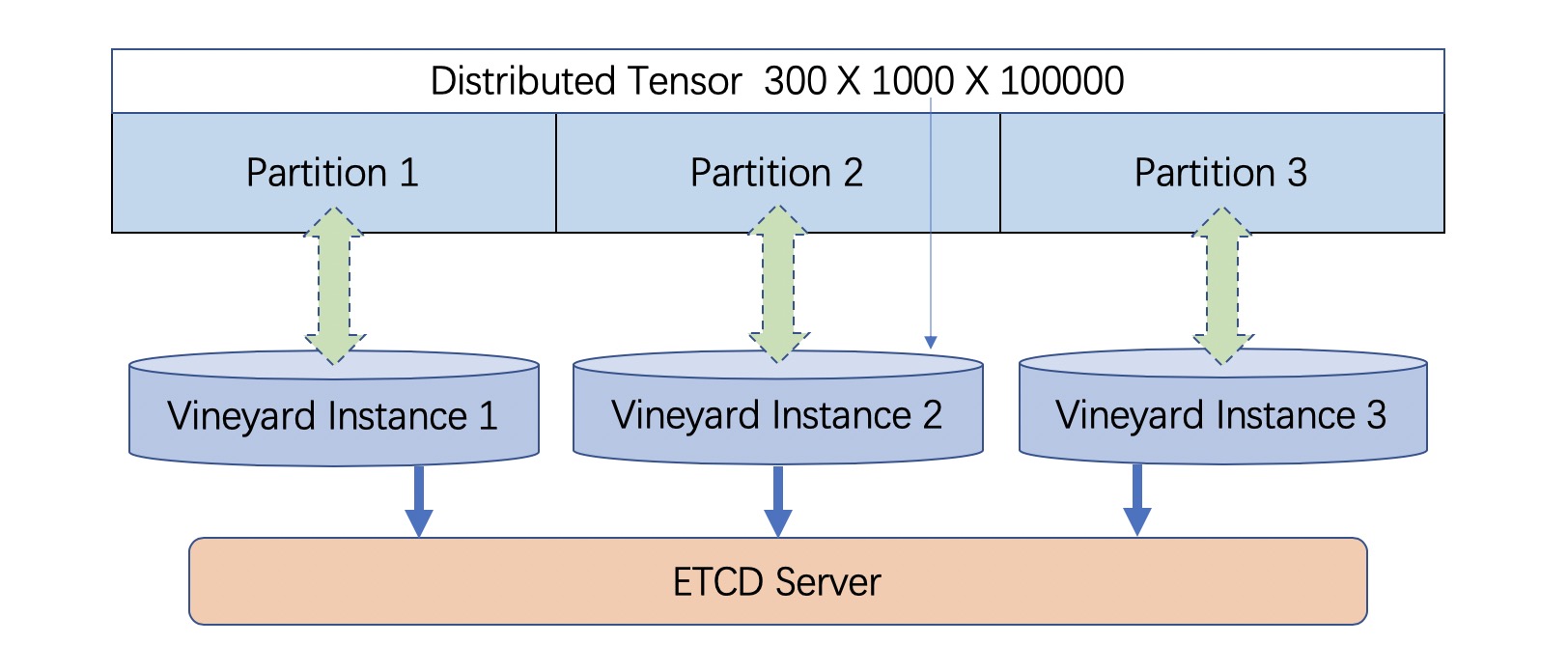
Distributed objects in vineyard¶
For example, consider a “Tensor” object that contains billions of columns and rows, making it too large to fit into a single machine. In such cases, the tensor can be split along the index or column axis, with each vineyard node holding a subset of chunks. Vineyard provides a logical view of the complete tensor, allowing distributed computation engines like Mars and GraphScope to process the data structure as a whole. .. TODO: add the collection APIs
Tip
See also the concepts of persistent objects in the following subsection. Refer to the following subsection for more information on the concept of persistent objects.
Transient vs. Persistent¶
As previously mentioned, vineyard objects’ metadata and payloads are managed separately by different components of the vineyard server. Payloads are designed to be shared with computing engines using local memory mapping. However, metadata may need to be inspected by clients connected to other vineyard instances, such as when forming a distributed object. In this case, the distributed object consists of a set of chunks placed on different vineyard instances. When retrieving the distributed objects from vineyard, computing engines may need to inspect the metadata of non-local pieces to understand the distribution of the entire dataset.
This requirement implies that metadata must be globally synchronized and accessible from clients connected to other vineyard instances. However, global synchronization is a costly operation, and numerous small key-value pairs can significantly increase the burden on the key-value store backend of our metadata services. To address this issue, we categorize objects as transient or persistent.
Transient objects are designed for cases where the object is known not to be part of a distributed object and will never need to be inspected by clients on other vineyard instances. Transient objects are useful for short-lived immediate values within the progress of a single computing engine.
Persistent objects are designed for cases where the object chunk will be used to form a larger distributed object, and the metadata is needed when applications inspect the distributed object. Persistent objects and distributed objects are commonly used to pass intermediate data between two distributed engines.
Caution
By default, objects are transient. We provide an API client.persist() that
can explicitly persist the metadata of the target object to etcd, ensuring its visibility
by clients connected to other instances in the cluster.
Builders and resolvers¶
Vineyard utilizes an extensible registry mechanism to enable users to easily integrate their data structures into the system. This design, which includes builders, resolvers, and drivers, allows users to create, resolve, and share their data structures across different systems and paradigms. Notably, even the core data structures and drivers in Vineyard follow this design.
Note
What is the registry mechanism?
The registry mechanism decouples methods from the definition of Vineyard data types. For builders and resolvers, this means users can flexibly register different implementations in various languages to build and resolve the same Vineyard data type. This enables data sharing between different systems and paradigms and allows for native language optimizations.
For drivers, the registry mechanism permits users to flexibly plug in functionality methods in different languages for Vineyard data types, providing the necessary capabilities for data types during the data analysis process.
Moreover, the registered methods can be implemented and optimized according to specific data analysis tasks, further enhancing efficiency.
Refer to Define Data Types in Python and Defining Custom Data Types in C++ for examples of how builders and resolvers are implemented in Python and C++, respectively.