an in-memory immutable data manager¶


Why bother?¶
Sharing intermediate data between systems in modern big data and AI workflows can be challenging, often causing significant bottlenecks in such jobs. Let’s consider the following fraud detection pipeline:
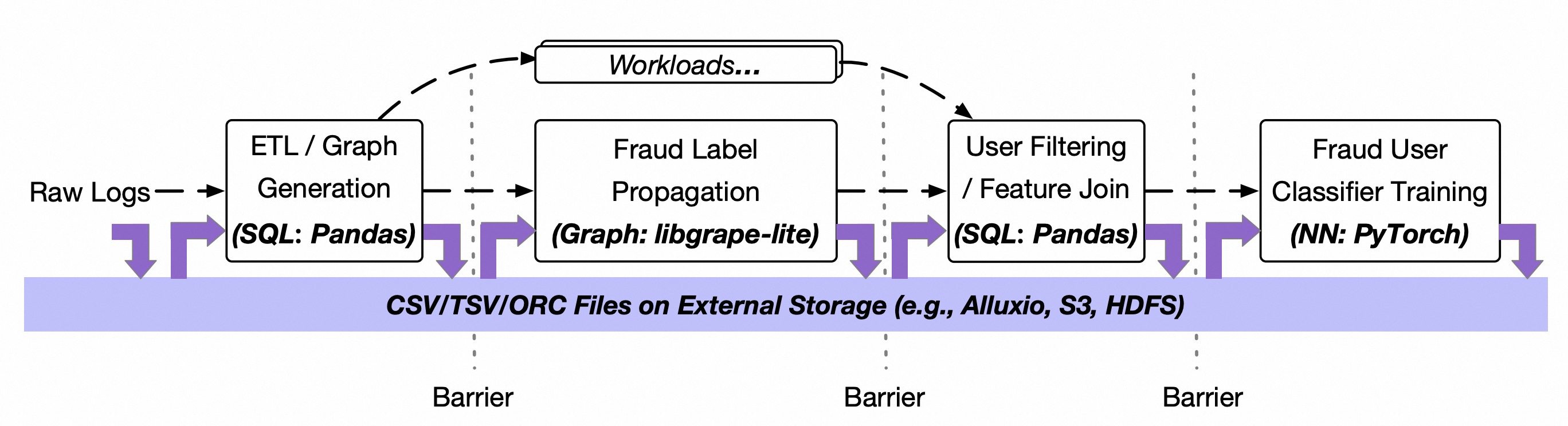
A real-life fraud detection job¶
From the pipeline, we observed:
Users usually prefer to program with dedicated computing systems for different tasks in the same applications, such as SQL and Python.
Integrating a new computing system into production environments demands high technical effort to align with existing production environments in terms of I/O, failover, etc.
Data could be polymorphic. Non-relational data, such as tensors, dataframes (in Pandas) and graphs/networks (in GraphScope) are becoming increasingly prevalent. Tables and SQL may not be the best way to store, exchange, or process them.
Transforming the data back and forth between different systems as “tables” could result in a significant overhead.
Saving/loading the data to/from the external storage requires numerous memory copies and incurs high IO costs.
What is Vineyard?¶
Vineyard (v6d) is an in-memory immutable data manager that offers out-of-the-box high-level abstraction and zero-copy sharing for distributed data in big data tasks, such as graph analytics (e.g., GraphScope), numerical computing (e.g., Mars), and machine learning.
Features¶
Efficient data sharing¶
Vineyard shares immutable data across different systems using shared memory without extra overheads, eliminating the overhead of serialization/deserialization and IO when exchanging immutable data between systems.
Out-of-the-box data abstraction¶
Vineyard defines a metadata-payload separated data model to capture the payload commonalities and method commonalities between sharable objects in different programming languages and different computing systems in a unified way.
The Code Generation for Boilerplate (Vineyard Component Description Language) is specifically designed to annotate sharable members and methods, enabling automatic generation of boilerplate code for minimal integration effort.
Pluggable I/O routines¶
In many big data analytical tasks, a substantial portion of the workload consists of boilerplate routines that are unrelated to the core computation. These routines include various IO adapters, data partition strategies, and migration jobs. Due to different data structure abstractions across systems, these routines are often not easily reusable, leading to increased complexity and redundancy.
Vineyard provides common manipulation routines for immutable data as drivers, which extend the capabilities of data structures by registering appropriate drivers. This enables out-of-the-box reuse of boilerplate components across diverse computation jobs.
Data orchestration on Kubernetes¶
Vineyard provides efficient distributed data sharing in cloud-native environments by embracing cloud-native big data processing. Kubernetes helps Vineyard leverage the scale-in/out and scheduling abilities of Kubernetes.
Use cases¶
Put and get arbitrary objects using Vineyard, in a zero-copy way!
Share large objects across computing systems.
Vineyard coordinates the flow of objects and jobs on Kubernetes based on data-aware scheduling.
Get started now!¶
Get started with Vineyard.
Deploy Vineyard on Kubernetes and accelerate big-data analytical workflows on cloud-native infrastructures.
Explore use cases and tutorials where Vineyard can bring added value.
Get involved and become part of the Vineyard community.
Frequently asked questions and discussions during the adoption of Vineyard.
Read the Paper¶
Wenyuan Yu, Tao He, Lei Wang, Ke Meng, Ye Cao, Diwen Zhu, Sanhong Li, Jingren Zhou. Vineyard: Optimizing Data Sharing in Data-Intensive Analytics. ACM SIG Conference on Management of Data (SIGMOD), industry, 2023.
.
Vineyard is a CNCF sandbox project and is made successful by its community.
