Data sharing with Vineyard on Kubernetes¶
If you want to share data between different workloads(pods or containers) on kubernetes, it’s a good idea to use vineyard as the data-sharing service. In this tutorial, we will show you how to share data between different containers or pods on kubernetes step by step.
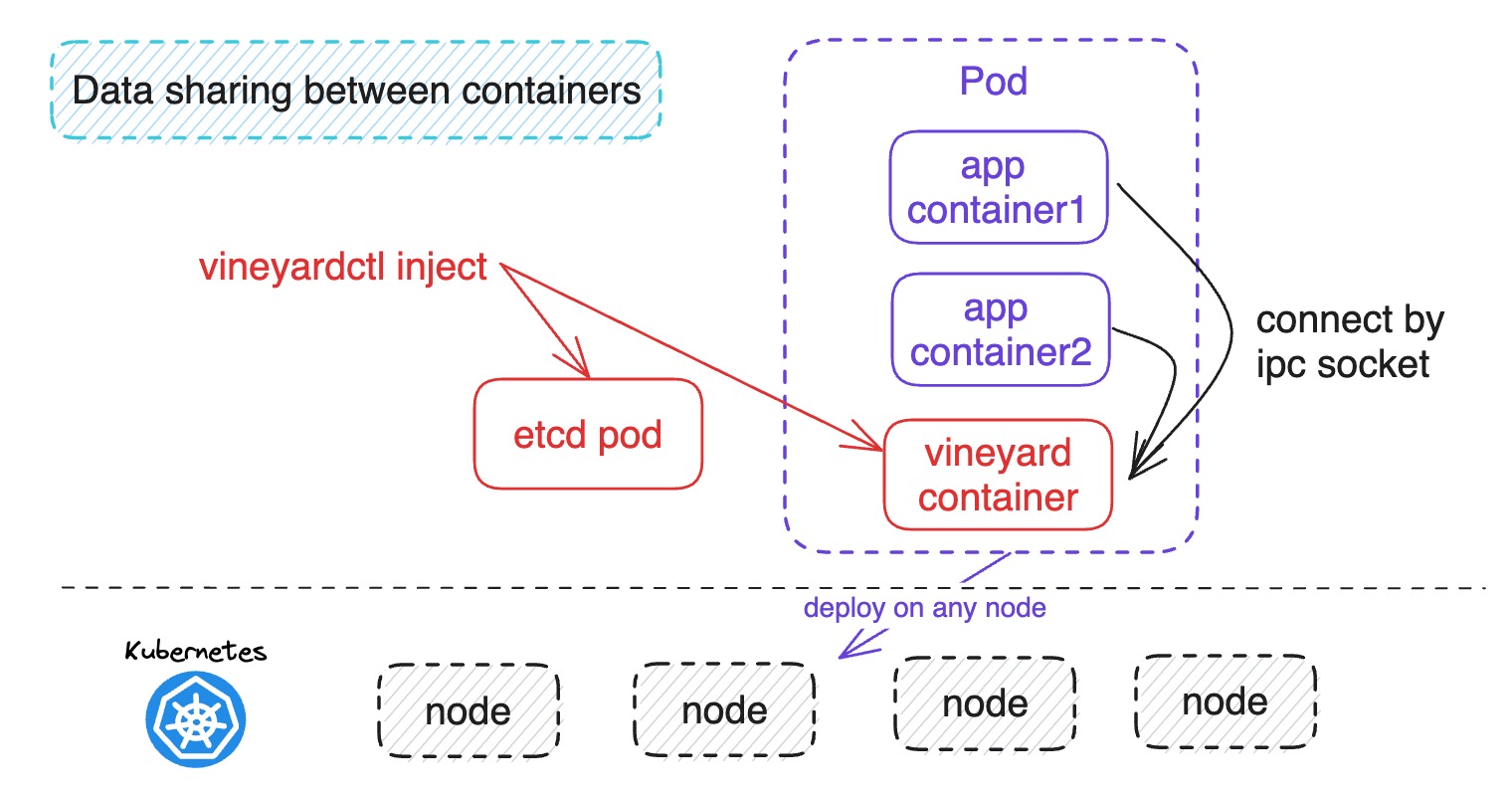
Data sharing between containers¶
From the above figure, the vineyardctl inject command will inject vineyard container into the app pod and the app containers will connect to the vineyard container to share the vineyard data.
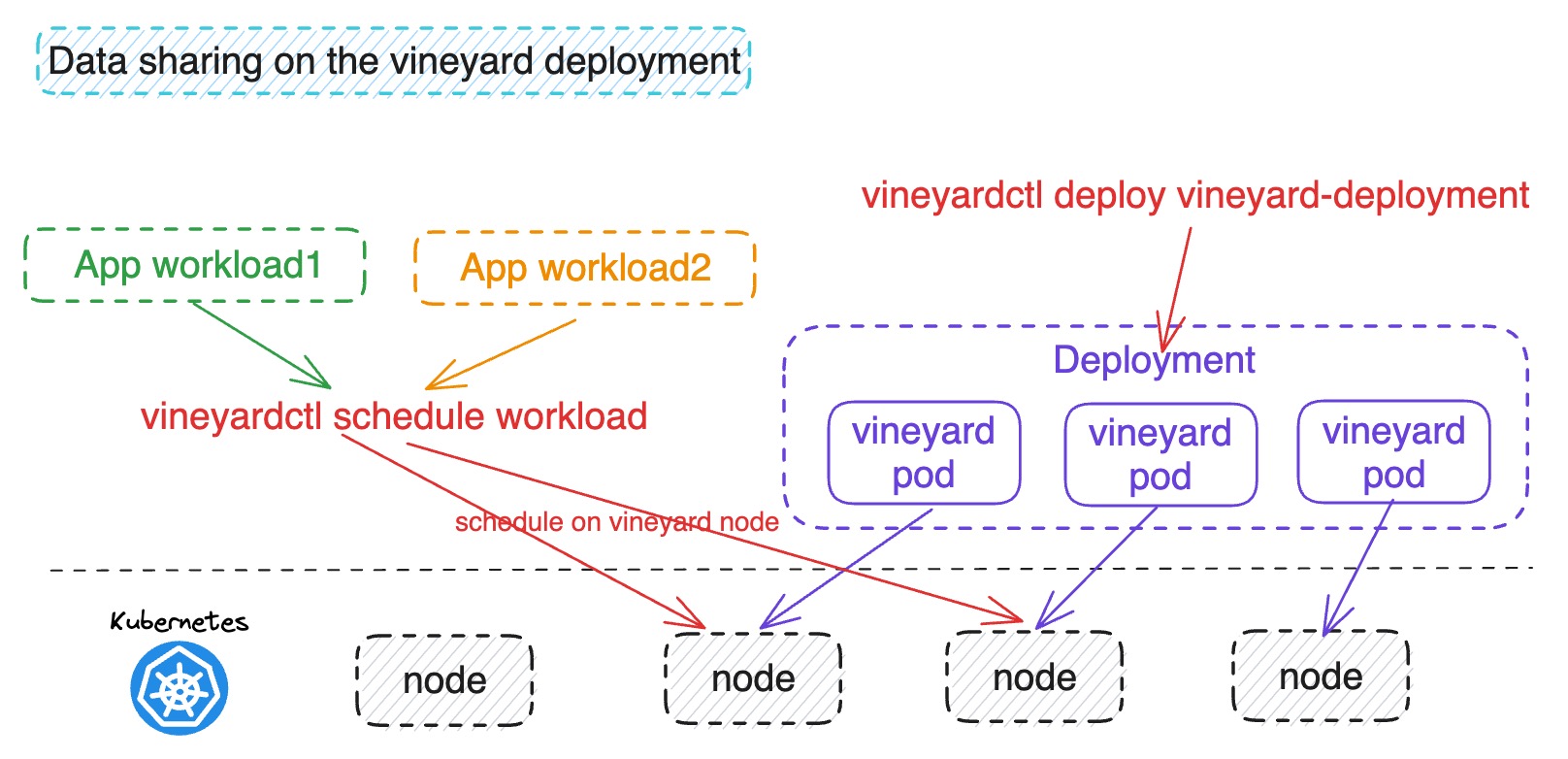
Data sharing on the vineyard deployment¶
From the above figure, the vineyardctl deploy vineyard-deployment command will deploy a vineyard deployment on the kubernetes cluster (default is 3 replicas) and the app pods will be scheduled to the vineyard deployment to share the vineyard data via the command vineyardctl schedule workload.
Prerequisites¶
A kubernetes cluster >= v1.19.
Install the latest vineyardctl command line tool refer to vineyardctl installation.
Data sharing between different containers¶
In this section, we will show you how to share data between different containers on kubernetes. Assuming you have a pod with two containers, one is a producer and the other is a consumer. The producer will generate some data and write it to vineyard, and the consumer will read the data from vineyard and do some computation.
Save the following yaml as pod.yaml.
$ cat << EOF >> pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: vineyard-producer-consumer
namespace: vineyard-test
spec:
containers:
- name: producer
image: python:3.10
command:
- bash
- -c
- |
pip install vineyard numpy pandas;
cat << EOF >> producer.py
import vineyard;
import numpy as np;
import pandas as pd;
client = vineyard.connect();
# put a pandas dataframe to vineyard
client.put(pd.DataFrame(np.random.randn(100, 4), columns=list('ABCD')), persist=True, name="test_dataframe");
# put a basic data unit to vineyard
client.put((1, 1.2345, 'xxxxabcd'), persist=True, name="test_basic_data_unit");
client.close()
EOF
python producer.py;
sleep infinity;
- name: consumer
image: python:3.10
command:
- bash
- -c
- |
# wait for the producer to finish
sleep 10;
pip install vineyard numpy pandas;
cat << EOF >> consumer.py
import vineyard;
client = vineyard.connect();
# get the pandas dataframe from vineyard
print(client.get(name="test_dataframe").sum())
# get the basic data unit from vineyard
print(client.get(name="test_basic_data_unit"))
client.close()
EOF
python consumer.py;
sleep infinity;
EOF
Use the vineyardctl to inject vineyard into the pod and apply them to the kubernetes cluster as follows.
# create the namespace
$ kubectl create ns vineyard-test
# get all injected resources
$ python3 -m vineyard.ctl inject -f pod.yaml | kubectl apply -f -
pod/vineyard-sidecar-etcd-0 created
service/vineyard-sidecar-etcd-0 created
service/vineyard-sidecar-etcd-service created
service/vineyard-sidecar-rpc created
pod/vineyard-producer-consumer created
Then you can get the logs of the consumer containers as follows.
# get the logs of the consumer container
$ kubectl logs -f vineyard-producer-consumer -n test -c consumer
A -30.168469
B -19.269489
C 6.332533
D -9.714950
dtype: float64
(1, 1.2345000505447388, 'xxxxabcd')
Data sharing between different pods¶
In this section, we will show you how to share data between different workloads on kubernetes. You are supposed to create a vineyard deployment and then deploy the application pods on the nodes where the vineyard deployment is running.
Deploy the vineyard deployment (default is 3 replicas) as follows.
# create the namespace if not exists
$ kubectl create ns vineyard-test
# create the vineyard deployment
$ python3 -m vineyard.ctl deploy vineyard-deployment --name vineyardd-sample -n vineyard-test
2023-07-21T15:42:25.981+0800 INFO vineyard cluster deployed successfully
Check the vineyard deployment status and the three vineyardd pods should run on the different nodes.
# check the pods status
$ kubectl get pod -lapp.vineyard.io/name=vineyardd-sample -n vineyard-test -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
vineyardd-sample-5fd45fdd66-fq55z 1/1 Running 0 3m37s 10.244.1.17 kind-worker3 <none> <none>
vineyardd-sample-5fd45fdd66-qjr5c 1/1 Running 0 3m37s 10.244.3.35 kind-worker <none> <none>
vineyardd-sample-5fd45fdd66-ssqb7 1/1 Running 0 3m37s 10.244.2.29 kind-worker2 <none> <none>
vineyardd-sample-etcd-0 1/1 Running 0 3m53s 10.244.1.16 kind-worker3 <none> <none>
Assume we have two pods, one is a producer and the other is a consumer.
The producer yaml file is as follows.
$ cat << EOF >> producer.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: producer
namespace: vineyard-test
spec:
selector:
matchLabels:
app: producer
replicas: 1
template:
metadata:
labels:
app: producer
spec:
containers:
- name: producer
image: python:3.10
command:
- bash
- -c
- |
pip install vineyard numpy pandas;
cat << EOF >> producer.py
import vineyard
import numpy as np
import pandas as pd
client = vineyard.connect()
client.put(pd.DataFrame(np.random.randn(100, 4), columns=list('ABCD')), persist=True, name="test_dataframe")
client.put((1, 1.2345, 'xxxxabcd'), persist=True, name="test_basic_data_unit");
client.close()
EOF
python producer.py;
sleep infinity;
EOF
The consumer yaml file is as follows.
$ cat << EOF >> consumer.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: consumer
namespace: vineyard-test
spec:
selector:
matchLabels:
app: consumer
replicas: 1
template:
metadata:
labels:
app: consumer
spec:
containers:
- name: consumer
image: python:3.10
command:
- bash
- -c
- |
pip install vineyard numpy pandas;
cat << EOF >> consumer.py
import vineyard
client = vineyard.connect()
dataframe_obj = client.get_name("test_dataframe")
print(client.get(dataframe_obj,fetch=True).sum())
unit_obj = client.get_name("test_basic_data_unit")
print(client.get(unit_obj,fetch=True))
client.close()
EOF
python consumer.py;
sleep infinity;
EOF
Use the vineyardctl to schedule the two workloads on the vineyard cluster.
# schedule the producer workload to the vineyard cluster and apply it to the kubernetes cluster
$ python3 -m vineyard.ctl schedule workload -f producer.yaml --vineyardd-name vineyardd-sample \
--vineyardd-namespace vineyard-test -o yaml | kubectl apply -f -
deployment.apps/producer created
# schedule the consumer workload to the vineyard cluster and apply it to the kubernetes cluster
$ python3 -m vineyard.ctl schedule workload -f consumer.yaml --vineyardd-name vineyardd-sample \
--vineyardd-namespace vineyard-test -o yaml | kubectl apply -f -
deployment.apps/consumer created
Check the logs of the consumer pods as follows.
$ kubectl logs -f $(kubectl get pod -lapp=consumer -n vineyard-test -o jsonpath='{.items[0].metadata.name}') -n vineyard-test
A 11.587912
B 12.059792
C 4.863514
D -2.682567
dtype: float64
(1, 1.2345000505447388, 'xxxxabcd')
From the above example, we can see the code of the consumer is quiet different from the previous sidecar example. As the consumer may be scheduled to different node from the producer with the default kubernetes scheduler, the client should get the remote object id by name and then fetch it from other vineyard nodes. For more details, please refer to the vineyard objects.