Vineyard Operator¶
Architecture¶
The following figure demonstrates the architecture of vineyard operator.
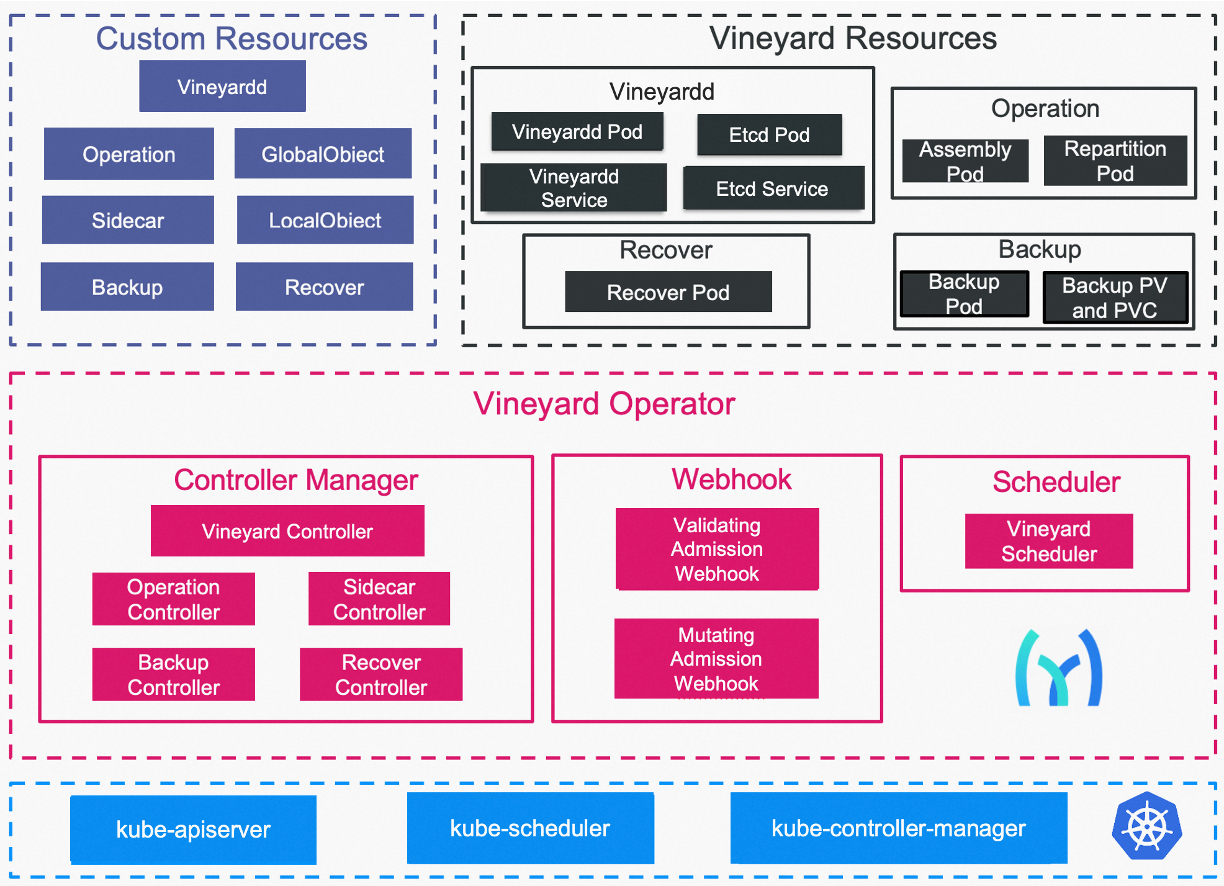
Architecture of vineyard operator¶
Create a vineyard Cluster¶
After successfully installing the vineyard operator (refer to Deploy on Kubernetes
for installation details), you can effortlessly create a vineyard cluster by utilizing
the Vineyardd CRD. The following example demonstrates the creation of a vineyard
cluster with 3 daemon replicas:
Note
The namespace of the vineyard cluster must be the same as the namespace of the vineyard operator, as the vineyard cluster will use the vineyard operator’s service account.
$ cat <<EOF | kubectl apply -f -
apiVersion: k8s.v6d.io/v1alpha1
kind: Vineyardd
metadata:
name: vineyardd-sample
# use the same namespace as the vineyard operator
namespace: vineyard-system
EOF
The vineyard-operator orchestrates the creation of a deployment for the required metadata
service backend (etcd), sets up appropriate services, and ultimately establishes a
deployment for 3-replica vineyard servers. Upon successful deployment, the following
components will be created and managed by the vineyard operator:
$ kubectl get all -n vineyard-system
Expected output
NAME READY STATUS RESTARTS AGE pod/etcd0 1/1 Running 0 48s pod/etcd1 1/1 Running 0 48s pod/etcd2 1/1 Running 0 48s pod/vineyard-controller-manager-5c6f4bc454-8xm8q 2/2 Running 0 72s pod/vineyardd-sample-5cc797668f-9ggr9 1/1 Running 0 48s pod/vineyardd-sample-5cc797668f-nhw7p 1/1 Running 0 48s pod/vineyardd-sample-5cc797668f-r56h7 1/1 Running 0 48s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/etcd-for-vineyard ClusterIP 10.96.174.41 <none> 2379/TCP 48s service/etcd0 ClusterIP 10.96.128.87 <none> 2379/TCP,2380/TCP 48s service/etcd1 ClusterIP 10.96.72.116 <none> 2379/TCP,2380/TCP 48s service/etcd2 ClusterIP 10.96.99.182 <none> 2379/TCP,2380/TCP 48s service/vineyard-controller-manager-metrics-service ClusterIP 10.96.240.173 <none> 8443/TCP 72s service/vineyard-webhook-service ClusterIP 10.96.41.132 <none> 443/TCP 72s service/vineyardd-sample-rpc ClusterIP 10.96.102.183 <none> 9600/TCP 48s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/vineyard-controller-manager 1/1 1 1 72s deployment.apps/vineyardd-sample 3/3 3 3 48s NAME DESIRED CURRENT READY AGE replicaset.apps/vineyard-controller-manager-5c6f4bc454 1 1 1 72s replicaset.apps/vineyardd-sample-5cc797668f 3 3 3 48s
Also, if you want to use the custom vineyard socket path and mount something like /dev to the vineyard container, you could use the following YAML file:
$ cat <<EOF | kubectl apply -f -
apiVersion: k8s.v6d.io/v1alpha1
kind: Vineyardd
metadata:
name: vineyardd-sample
spec:
vineyard:
# only for host path
socket: /your/vineyard/socket/path
# you should set the securityContext.privileged to true
# if you want to mount /dev to the vineyard container
securityContext:
privileged: true
volumes:
- name: dev-volumes
hostPath:
path: /dev
volumeMounts:
- name: dev-volumes
mountPath: /dev
EOF
For detailed configuration entries of vineyardd, please refer to vineyardd CRD.
Installing vineyard as sidecar¶
Vineyard can be seamlessly integrated as a sidecar container within a pod. We offer the Sidecar Custom Resource Definition (CRD) for configuring and managing the sidecar container. The Sidecar CRD shares many similarities with the Vineyardd CRD, and all available configurations can be found in the Sidecar CRD.
Besides, We provide some labels and annotations to help users to use the sidecar in vineyard operator. The following are all labels that we provide:
Name |
Yaml Fields |
Description |
|---|---|---|
“sidecar.v6d.io/enabled” |
labels |
Enable the sidecar. |
“sidecar.v6d.io/name” |
annotations |
The name of sidecar cr. If the name is default, the default sidecar cr will be created. |
There are two methods to install vineyard as a sidecar:
Utilize the default sidecar configuration. Users should add two annotations, sidecar.v6d.io/enabled: true and sidecar.v6d.io/name: default, to their app’s YAML. This will create a default sidecar Custom Resource (CR) for observation.
Employ the custom sidecar configuration. Users must first create a custom sidecar CR, such as sidecar-demo, and then add two annotations, sidecar.v6d.io/enabled: true and sidecar.v6d.io/name: sidecar-demo, to their app’s YAML.
The following example demonstrates how to install vineyard as a sidecar container within a pod. First, install the vineyard operator according to the previous steps, and then create a namespace with the specific label sidecar-injection: enabled to enable the sidecar.
$ kubectl create namespace vineyard-job
$ kubectl label namespace vineyard-job sidecar-injection=enabled
Next, use the following YAML to inject the default sidecar into the pod.
Note
Please configure the command field of your app container to be in the format [“/bin/sh” or “/bin/bash”, “-c”, (your app command)]. After injecting the vineyard sidecar, the command field will be modified to [“/bin/sh” or “/bin/bash”, “-c”, while [ ! -e /var/run/vineyard.sock ]; do sleep 1; done;” + (your app command)] to ensure that the vineyard sidecar is ready before the app container starts.
$ cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: job-deployment
namespace: vineyard-job
spec:
selector:
matchLabels:
app: job-deployment
replicas: 2
template:
metadata:
annotations:
sidecar.v6d.io/name: "default"
labels:
app: job-deployment
sidecar.v6d.io/enabled: "true"
spec:
containers:
- name: job
image: ghcr.io/v6d-io/v6d/sidecar-job
imagePullPolicy: IfNotPresent
command: ["/bin/sh", "-c", "python3 /job.py"]
env:
- name: JOB_NAME
value: v6d-workflow-demo-job
EOF
Next, you could see the sidecar container injected into the pod.
# get the default sidecar cr
$ kubectl get sidecar app-job-deployment-default-sidecar -n vineyard-job -o yaml
apiVersion: k8s.v6d.io/v1alpha1
kind: Sidecar
metadata:
# the default sidecar's name is your label selector + "-default-sidecar"
name: app-job-deployment-default-sidecar
namespace: vineyard-job
spec:
metric:
enable: false
image: vineyardcloudnative/vineyard-grok-exporter:latest
imagePullPolicy: IfNotPresent
replicas: 2
selector: app=job-deployment
service:
port: 9600
selector: rpc.vineyardd.v6d.io/rpc=vineyard-rpc
type: ClusterIP
vineyard:
image: vineyardcloudnative/vineyardd:latest
imagePullPolicy: IfNotPresent
size: ""
socket: /var/run/vineyard.sock
spill:
name: ""
path: ""
persistentVolumeClaimSpec:
resources: {}
persistentVolumeSpec: {}
spillLowerRate: "0.3"
spillUpperRate: "0.8"
streamThreshold: 80
syncCRDs: true
# get the injected Pod, here we only show the important part of the Pod
$ kubectl get pod -l app=job-deployment -n vineyard-job -o yaml
apiVersion: v1
kind: Pod
metadata:
name: job-deployment-55664458f8-h4jzk
namespace: vineyard-job
spec:
containers:
- command:
- /bin/sh
- -c
- while [ ! -e /var/run/vineyard.sock ]; do sleep 1; done;python3 /job.py
env:
- name: JOB_NAME
value: v6d-workflow-demo-job
image: ghcr.io/v6d-io/v6d/sidecar-job
imagePullPolicy: IfNotPresent
name: job
volumeMounts:
- mountPath: /var/run
name: vineyard-socket
- command:
- /bin/bash
- -c
- |
/usr/local/bin/vineyardd --sync_crds true --socket /var/run/vineyard.sock
--stream_threshold 80 --etcd_cmd etcd --etcd_prefix /vineyard
--etcd_endpoint http://etcd-for-vineyard:2379
env:
- name: VINEYARDD_UID
value: 7b0c2ec8-49f3-4f8f-9e5f-8576a4dc4321
- name: VINEYARDD_NAME
value: app-job-deployment-with-default-sidecar-default-sidecar
- name: VINEYARDD_NAMESPACE
value: vineyard-job
image: vineyardcloudnative/vineyardd:latest
imagePullPolicy: IfNotPresent
name: vineyard-sidecar
ports:
- containerPort: 9600
name: vineyard-rpc
protocol: TCP
volumeMounts:
- mountPath: /var/run
name: vineyard-socket
volumes:
- emptyDir: {}
name: vineyard-socket
# get the number of injected sidecar
$ kubectl get sidecar -A
NAMESPACE NAME CURRENT DESIRED
vineyard-job app-job-deployment-with-default-sidecar-default-sidecar 2 2
If you don’t want to use the default sidecar configuration, you could create a custom sidecar cr as follows:
Note
Please make sure your custom sidecar cr is created before deploying your app workload and keep the same namespace with your app workload.
$ cat <<EOF | kubectl apply -f -
apiVersion: k8s.v6d.io/v1alpha1
kind: Sidecar
metadata:
name: sidecar-sample
namespace: vineyard-job
spec:
replicas: 2
selector: app=job-deployment-with-custom-sidecar
vineyard:
socket: /var/run/vineyard.sock
size: 1024Mi
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: job-deployment-with-custom-sidecar
namespace: vineyard-job
spec:
selector:
matchLabels:
app: job-deployment-with-custom-sidecar
replicas: 2
template:
metadata:
annotations:
sidecar.v6d.io/name: "sidecar-sample"
labels:
app: job-deployment-with-custom-sidecar
sidecar.v6d.io/enabled: "true"
spec:
containers:
- name: job
image: ghcr.io/v6d-io/v6d/sidecar-job
imagePullPolicy: IfNotPresent
command: ["/bin/sh", "-c", "python3 /job.py"]
env:
- name: JOB_NAME
value: v6d-workflow-demo-job
EOF
Also, if you want to use the custom vineyard socket path and mount something like /dev to the vineyard container, you could use the following YAML file:
$ cat <<EOF | kubectl apply -f -
apiVersion: k8s.v6d.io/v1alpha1
kind: Sidecar
metadata:
name: sidecar-sample
namespace: vineyard-job
spec:
replicas: 2
selector: app=job-deployment-with-custom-sidecar
vineyard:
socket: /var/run/vineyard.sock
size: 1024Mi
# you should set the securityContext.privileged to true
# if you want to mount /dev to the vineyard container
securityContext:
privileged: true
volumes:
- name: dev-volumes
hostPath:
path: /dev
volumeMounts:
- name: dev-volumes
mountPath: /dev
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: job-deployment-with-custom-sidecar
namespace: vineyard-job
spec:
selector:
matchLabels:
app: job-deployment-with-custom-sidecar
replicas: 2
template:
metadata:
annotations:
sidecar.v6d.io/name: "sidecar-sample"
labels:
app: job-deployment-with-custom-sidecar
sidecar.v6d.io/enabled: "true"
spec:
containers:
- name: job
image: ghcr.io/v6d-io/v6d/sidecar-job
imagePullPolicy: IfNotPresent
command: ["/bin/sh", "-c", "python3 /job.py"]
env:
- name: JOB_NAME
value: v6d-workflow-demo-job
EOF
For more details about how to use the sidecar, please refer to the sidecar e2e test for more inspiration.
Objects in Vineyard¶
Vineyard objects are exposed to the Kubernetes control panel as Custom Resource Definitions (CRDs). In vineyard, objects are abstracted as global objects and local objects (refer to Objects), which are represented by the GlobalObject and LocalObject CRDs in the vineyard operator:
GlobalObject¶
The GlobalObject custom resource definition (CRD) declaratively defines a global object within a vineyard cluster, and all configurations can be found in the GlobalObject CRD.
In general, the GlobalObjects are created as intermediate objects when deploying users’ applications. You could get them as follows.
$ kubectl get globalobjects -A
NAMESPACE NAME ID NAME SIGNATURE TYPENAME
vineyard-system o001bcbcea406acd0 o001bcbcea406acd0 s001bcbcea4069f60 vineyard::GlobalDataFrame
vineyard-system o001bcc19dbfc9c34 o001bcc19dbfc9c34 s001bcc19dbfc8d7a vineyard::GlobalDataFrame
LocalObject¶
The LocalObject custom resource definition (CRD) declaratively defines the local object in a Kubernetes cluster, and you can find all configurations in the LocalObject CRD.
The LocalObjects are also intermediate objects just like the GlobalObjects, and you could get them as follows.
$ kubectl get localobjects -A
Expected output
NAMESPACE NAME ID NAME SIGNATURE TYPENAME INSTANCE HOSTNAME vineyard-system o001bcbce202ab390 o001bcbce202ab390 s001bcbce202aa6f6 vineyard::DataFrame 0 kind-worker2 vineyard-system o001bcbce21d273e4 o001bcbce21d273e4 s001bcbce21d269c2 vineyard::DataFrame 1 kind-worker vineyard-system o001bcbce24606f6a o001bcbce24606f6a s001bcbce246067fc vineyard::DataFrame 2 kind-worker3
Vineyard Scheduler¶
The Vineyard operator includes a scheduler plugin designed to efficiently schedule workloads on Vineyard by placing them as close as possible to their input data, thereby reducing data migration costs. The Vineyard scheduler plugin is developed based on the Kubernetes Scheduling Framework, and its overall scheduling strategy can be summarized as follows:
Note
Vineyard Scheduler is compatible with Kubernetes versions 1.19 to 1.24. Ensure your Kubernetes cluster is within this version range for proper functionality.
All Vineyard workloads can only be deployed on nodes where the Vineyard daemon server is present.
If a workload does not depend on any other workload, it will be scheduled using a round-robin approach. For example, if a workload has 3 replicas and there are 3 nodes with Vineyard daemon servers, the first replica will be scheduled on the first node, the second replica on the second node, and so on.
If a workload depends on other workloads, it will be scheduled using a best-effort policy. Assuming a workload produces N chunks during its lifecycle, and there are M nodes with Vineyard daemon servers, the best-effort policy will attempt to make the next workload consume
M/N: chunks. For instance, imagine a workload produces 12 chunks with the following distribution:node1: 0-8 node2: 9-11 node3: 12
The next workload has 3 replicas, and the best-effort policy will schedule it as follows:
replica1 -> node1 (consume 0-3 chunks) replica2 -> node1 (consume 4-7 chunks) replica3 -> node2 (consume 9-11 chunks, the other chunks will be migrated to the node)
Utilizing the Vineyard Scheduler¶
The Vineyard scheduler is integrated into the Vineyard operator and deployed alongside it. This scheduler plugin relies on specific annotations and labels to provide necessary input information. The required configurations are listed below in a clear and comprehensive manner:
Scheduler Plugin Configurations
Name
Yaml Fields
Description
“scheduling.k8s.v6d.io/required”
annotations
All jobs required by the job. If there are more than two tasks, use the concatenator ‘,’ to concatenate them into a string. E.g. job1,job2,job3. If there is no required jobs, set none.
“scheduling.k8s.v6d.io/vineyardd”
labels
The name or namespaced name of vineyardd. e.g., vineyard-sample or vineyard-system/vineyard-sample.
“scheduling.k8s.v6d.io/job “”
labels
The job name.
“schedulerName”
spec
The vineyard scheduler’s name, and the default value is vineyard-scheduler.
In this section, we will demonstrate a comprehensive example of utilizing the Vineyard scheduler. To begin, ensure that the Vineyard operator and Vineyard daemon server are installed by following the steps outlined earlier. Then, proceed to deploy workflow-job1 as shown below.
$ kubectl create ns vineyard-job
$ cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: v6d-workflow-demo-job1-deployment
namespace: vineyard-job
spec:
selector:
matchLabels:
app: v6d-workflow-demo-job1
replicas: 2
template:
metadata:
labels:
app: v6d-workflow-demo-job1
# vineyardd's name
scheduling.k8s.v6d.io/vineyardd-namespace: vineyard-system
scheduling.k8s.v6d.io/vineyardd: vineyardd-sample
# job name
scheduling.k8s.v6d.io/job: v6d-workflow-demo-job1
spec:
# vineyard scheduler name
schedulerName: vineyard-scheduler
containers:
- name: job1
image: ghcr.io/v6d-io/v6d/workflow-job1
# please set the JOB_NAME env, it will be used by vineyard scheduler
env:
- name: JOB_NAME
value: v6d-workflow-demo-job1
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: /var/run
name: vineyard-sock
volumes:
- name: vineyard-sock
hostPath:
path: /var/run/vineyard-kubernetes/vineyard-system/vineyardd-sample
EOF
We can see the created job and the objects produced by it:
$ kubectl get all -n vineyard-job
NAME READY STATUS RESTARTS AGE
pod/v6d-workflow-demo-job1-deployment-6f479d695b-698xb 1/1 Running 0 3m16s
pod/v6d-workflow-demo-job1-deployment-6f479d695b-7zrw6 1/1 Running 0 3m16s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/v6d-workflow-demo-job1-deployment 2/2 2 2 3m16s
NAME DESIRED CURRENT READY AGE
replicaset.apps/v6d-workflow-demo-job1-deployment-6f479d695b 2 2 2 3m16s
$ kubectl get globalobjects -n vineyard-system
NAME ID NAME SIGNATURE TYPENAME
o001c87014cf03c70 o001c87014cf03c70 s001c87014cf03262 vineyard::Sequence
o001c8729e49e06b8 o001c8729e49e06b8 s001c8729e49dfbb4 vineyard::Sequence
$ kubectl get localobjects -n vineyard-system
NAME ID NAME SIGNATURE TYPENAME INSTANCE HOSTNAME
o001c87014ca81924 o001c87014ca81924 s001c87014ca80acc vineyard::Tensor<int64> 1 kind-worker2
o001c8729e4590626 o001c8729e4590626 s001c8729e458f47a vineyard::Tensor<int64> 2 kind-worker3
# when a job is scheduled, the scheduler will create a configmap to record the globalobject id
# that the next job will consume.
$ kubectl get configmap v6d-workflow-demo-job1 -n vineyard-job -o yaml
apiVersion: v1
data:
kind-worker3: o001c8729e4590626
v6d-workflow-demo-job1: o001c8729e49e06b8
kind: ConfigMap
...
Then deploy the workflow-job2 as follows.
$ cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: v6d-workflow-demo-job2-deployment
namespace: vineyard-job
spec:
selector:
matchLabels:
app: v6d-workflow-demo-job2
replicas: 3
template:
metadata:
annotations:
# required jobs
scheduling.k8s.v6d.io/required: v6d-workflow-demo-job1
labels:
app: v6d-workflow-demo-job2
# vineyardd's name
scheduling.k8s.v6d.io/vineyardd-namespace: vineyard-system
scheduling.k8s.v6d.io/vineyardd: vineyardd-sample
# job name
scheduling.k8s.v6d.io/job: v6d-workflow-demo-job2
spec:
# vineyard scheduler name
schedulerName: vineyard-scheduler
containers:
- name: job2
image: ghcr.io/v6d-io/v6d/workflow-job2
imagePullPolicy: IfNotPresent
env:
- name: JOB_NAME
value: v6d-workflow-demo-job2
# pass node name to the environment
- name: NODENAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
# Notice, vineyard operator will create a configmap to pass the global object id produced by the previous job.
# Please set the configMapRef, it's name is the same as the job name.
envFrom:
- configMapRef:
name: v6d-workflow-demo-job1
volumeMounts:
- mountPath: /var/run
name: vineyard-sock
volumes:
- name: vineyard-sock
hostPath:
path: /var/run/vineyard-kubernetes/vineyard-system/vineyardd-sample
EOF
Now you can see that both jobs have been scheduled and become running:
$ kubectl get all -n vineyard-job
Expected output
NAME READY STATUS RESTARTS AGE pod/v6d-workflow-demo-job1-deployment-6f479d695b-698xb 1/1 Running 0 8m12s pod/v6d-workflow-demo-job1-deployment-6f479d695b-7zrw6 1/1 Running 0 8m12s pod/v6d-workflow-demo-job2-deployment-b5b58cbdc-4s7b2 1/1 Running 0 6m24s pod/v6d-workflow-demo-job2-deployment-b5b58cbdc-cd5v2 1/1 Running 0 6m24s pod/v6d-workflow-demo-job2-deployment-b5b58cbdc-n6zvm 1/1 Running 0 6m24s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/v6d-workflow-demo-job1-deployment 2/2 2 2 8m12s deployment.apps/v6d-workflow-demo-job2-deployment 3/3 3 3 6m24s NAME DESIRED CURRENT READY AGE replicaset.apps/v6d-workflow-demo-job1-deployment-6f479d695b 2 2 2 8m12s replicaset.apps/v6d-workflow-demo-job2-deployment-b5b58cbdc 3 3 3 6m24s
The above is the process of running the workload based on the vineyard scheduler, and it’s same as the workflow e2e test. What’s more, you could refer to the workflow demo to dig into what happens in the container.
Operations and drivers¶
The Operation custom resource definition (CRD) elegantly defines the configurable pluggable drivers, primarily assembly and repartition, within a Kubernetes cluster. You could refer the Operation CRD to get more details.
The Operation Custom Resource (CR) is created by the vineyard scheduler while scheduling vineyard jobs. You can retrieve the created Operation CRs as follows:
$ kubectl get operation -A
NAMESPACE NAME OPERATION TYPE STATE
vineyard-job dask-repartition-job2-bbf596bf4-985vc repartition dask
Currently, the vineyard operator includes three pluggable drivers: checkpoint, assembly, and repartition. The following sections provide a brief introduction to each of these drivers.
Checkpoint¶
Vineyard currently supports two types of checkpoint drivers:
Active checkpoint - Serialization: Users can store data in temporary or persistent storage for checkpoint purposes using the API (vineyard.io.serialize/deserialize). Note that the serialization process is triggered by the user within the application image, and the volume is also created by the user. Therefore, it is not managed by the vineyard operator.
Passive checkpoint - Spill: Vineyard now supports spilling data from memory to storage when the data size exceeds the available memory capacity. There are two watermarks for memory spilling: the low watermark and the high watermark. When the data size surpasses the high watermark, vineyardd will spill the excess data to storage until it reaches the low watermark.
Triggering a checkpoint job¶
Now, the checkpoint driver (Spill) is configured within the vineyardd Custom Resource Definition (CRD). To create a default vineyardd daemon server with the spill mechanism enabled, use the following YAML file:
Note
The spill mechanism supports temporary storage (HostPath) and persistent storage (PersistentVolume)
$ cat <<EOF | kubectl apply -f -
apiVersion: k8s.v6d.io/v1alpha1
kind: Vineyardd
metadata:
name: vineyardd-sample
# use the same namespace as the vineyard operator
namespace: vineyard-system
spec:
vineyard:
# spill configuration
spill:
name: spill-path
# please make sure the path exists
path: /var/vineyard/spill
spillLowerRate: "0.3"
spillUpperRate: "0.8"
persistentVolumeSpec:
storageClassName: manual
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
hostPath:
path: /var/vineyard/spill
persistentVolumeClaimSpec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 512Mi
EOF
For a comprehensive understanding of the checkpoint mechanism in the vineyard operator, please refer to the checkpoint examples. Additionally, the serialize e2e test and the spill e2e test can provide valuable insights on how to effectively utilize the checkpoint mechanism within a workflow.
Assembly¶
In real-world scenarios, workloads often involve various computing engines. Some of these engines support stream types to accelerate data processing, while others do not. To ensure the seamless operation of the workload, an assembly mechanism is required to convert the stream type into a chunk type. This conversion enables subsequent computing engines that do not support stream types to read the metadata generated by the previous engine.
Triggering an assembly job¶
To reduce the load on the Kubernetes API Server, we offer a namespace selector for assembly. The assembly driver will only be applied to namespaces with the specific label operation-injection: enabled. Therefore, ensure that the application’s namespace has this label before using the assembly mechanism.
We provide several labels to assist users in utilizing the assembly mechanism in the vineyard operator. The following are the available labels:
Assembly Drivers Configurations
Name
Yaml Fields
Description
“assembly.v6d.io/enabled”
labels
If the job needs an assembly operation before deploying it, then set true.
“assembly.v6d.io/type”
labels
There are two types in assembly operation, local only for localobject(stream on the same node), distributed for globalobject(stream on different nodes).
In this example, we demonstrate how to utilize the assembly mechanism in the vineyard operator. We have a workflow consisting of two workloads: the first workload processes a stream, and the second workload processes a chunk. The assembly mechanism is used to convert the stream output from the first workload into a chunk format that can be consumed by the second workload. The following YAML file represents the assembly workload1:
Note
Ensure that the vineyard operator and vineyardd are installed before executing the following YAML file.
$ kubectl create namespace vineyard-job
$ cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: assembly-job1
namespace: vineyard-job
spec:
selector:
matchLabels:
app: assembly-job1
replicas: 1
template:
metadata:
labels:
app: assembly-job1
# this label represents the vineyardd's name that need to be used
scheduling.k8s.v6d.io/vineyardd-namespace: vineyard-system
scheduling.k8s.v6d.io/vineyardd: vineyardd-sample
scheduling.k8s.v6d.io/job: assembly-job1
spec:
schedulerName: vineyard-scheduler
containers:
- name: assembly-job1
image: ghcr.io/v6d-io/v6d/assembly-job1
env:
- name: JOB_NAME
value: assembly-job1
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: /var/run
name: vineyard-sock
volumes:
- name: vineyard-sock
hostPath:
path: /var/run/vineyard-kubernetes/vineyard-system/vineyardd-sample
EOF
# we can get the localobjects produced by the first workload, it's a stream type.
$ kubectl get localobjects -n vineyard-system
NAME ID NAME SIGNATURE TYPENAME INSTANCE HOSTNAME
o001d1b280049b146 o001d1b280049b146 s001d1b280049a4d4 vineyard::RecordBatchStream 0 kind-worker2
From the output above, it is evident that the localobjects generated by the first workload are of the stream type. Next, we will deploy the second workload utilizing the assembly mechanism. The following YAML file represents the assembly workload2:
# remember label the namespace with the label `operation-injection: enabled` to
# enable pluggable drivers.
$ kubectl label namespace vineyard-job operation-injection=enabled
$ cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: assembly-job2
namespace: vineyard-job
spec:
selector:
matchLabels:
app: assembly-job2
replicas: 1
template:
metadata:
annotations:
scheduling.k8s.v6d.io/required: assembly-job1
labels:
app: assembly-job2
assembly.v6d.io/enabled: "true"
assembly.v6d.io/type: "local"
# this label represents the vineyardd's name that need to be used
scheduling.k8s.v6d.io/vineyardd-namespace: vineyard-system
scheduling.k8s.v6d.io/vineyardd: vineyardd-sample
scheduling.k8s.v6d.io/job: assembly-job2
spec:
schedulerName: vineyard-scheduler
containers:
- name: assembly-job2
image: ghcr.io/v6d-io/v6d/assembly-job2
env:
- name: JOB_NAME
value: assembly-job2
- name: REQUIRED_JOB_NAME
value: assembly-job1
envFrom:
- configMapRef:
name: assembly-job1
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: /var/run
name: vineyard-sock
volumes:
- name: vineyard-sock
hostPath:
path: /var/run/vineyard-kubernetes/vineyard-system/vineyardd-sample
EOF
Upon deploying the second workload, it remains in a pending state. This indicates that the scheduler has identified the need for an assembly operation, and consequently, the corresponding assembly operation Custom Resource (CR) will be created.
# get all workloads, the job2 is pending as it needs an assembly operation.
$ kubectl get pod -n vineyard-job
NAME READY STATUS RESTARTS AGE
assembly-job1-86c99c995f-nzns8 1/1 Running 0 2m
assembly-job2-646b78f494-cvz2w 0/1 Pending 0 53s
# the assembly operation CR is created by the scheduler.
$ kubectl get operation -A
NAMESPACE NAME OPERATION TYPE STATE
vineyard-job assembly-job2-646b78f494-cvz2w assembly local
During the assembly operation, the Operation Controller will create a job to run assembly operation. We can get the objects produced by the job.
# get the assembly operation job
$ kubectl get job -n vineyard-job
NAMESPACE NAME COMPLETIONS DURATION AGE
vineyard-job assemble-o001d1b280049b146 1/1 26s 119s
# get the pod
$ kubectl get pod -n vineyard-job
NAME READY STATUS RESTARTS AGE
assemble-o001d1b280049b146-fzws7 0/1 Completed 0 5m55s
assembly-job1-86c99c995f-nzns8 1/1 Running 0 4m
assembly-job2-646b78f494-cvz2w 0/1 Pending 0 5m
# get the localobjects produced by the job
$ kubectl get localobjects -l k8s.v6d.io/created-podname=assemble-o001d1b280049b146-fzws7 -n vineyard-system
NAME ID NAME SIGNATURE TYPENAME INSTANCE HOSTNAME
o001d1b56f0ec01f8 o001d1b56f0ec01f8 s001d1b56f0ebf578 vineyard::DataFrame 0 kind-worker2
o001d1b5707c74e62 o001d1b5707c74e62 s001d1b5707c742e0 vineyard::DataFrame 0 kind-worker2
o001d1b571f47cfe2 o001d1b571f47cfe2 s001d1b571f47c3c0 vineyard::DataFrame 0 kind-worker2
o001d1b5736a6fd6c o001d1b5736a6fd6c s001d1b5736a6f1cc vineyard::DataFrame 0 kind-worker2
o001d1b574d9b94ae o001d1b574d9b94ae s001d1b574d9b8a9e vineyard::DataFrame 0 kind-worker2
o001d1b5765629cbc o001d1b5765629cbc s001d1b57656290a8 vineyard::DataFrame 0 kind-worker2
o001d1b57809911ce o001d1b57809911ce s001d1b57809904e0 vineyard::DataFrame 0 kind-worker2
o001d1b5797a9f958 o001d1b5797a9f958 s001d1b5797a9ee82 vineyard::DataFrame 0 kind-worker2
o001d1b57add9581c o001d1b57add9581c s001d1b57add94e62 vineyard::DataFrame 0 kind-worker2
o001d1b57c53875ae o001d1b57c53875ae s001d1b57c5386a22 vineyard::DataFrame 0 kind-worker2
# get the globalobjects produced by the job
$ kubectl get globalobjects -l k8s.v6d.io/created-podname=assemble-o001d1b280049b146-fzws7 -n vineyard-system
NAME ID NAME SIGNATURE TYPENAME
o001d1b57dc2c74ee o001d1b57dc2c74ee s001d1b57dc2c6a4a vineyard::Sequence
Each stream will be transformed into a globalobject. To make the second workload obtain the globalobject generated by the assembly operation, the vineyard scheduler will create a configmap to store the globalobject id as follows.
$ kubectl get configmap assembly-job1 -n vineyard-job -o yaml
apiVersion: v1
data:
assembly-job1: o001d1b57dc2c74ee
kind: ConfigMap
...
Upon completion of the assembly operation, the scheduler will reschedule the second workload, allowing it to be successfully deployed as shown below:
$ kubectl get pod -n vineyard-job
NAME READY STATUS RESTARTS AGE
assemble-o001d1b280049b146-fzws7 0/1 Completed 0 9m55s
assembly-job1-86c99c995f-nzns8 1/1 Running 0 8m
assembly-job2-646b78f494-cvz2w 1/1 Running 0 9m
The assembly operation process is demonstrated in the local assembly e2e test. For more details, please refer to the assembly demo and local assembly operation.
Additionally, we also support distributed assembly operation. You can explore the distributed assembly e2e test for further insights.
Repartitioning¶
Repartitioning is a mechanism that adjusts the distribution of data across the Vineyard cluster. It is particularly useful when the number of workers cannot accommodate the required number of partitions. For example, if a workload creates 4 partitions, but the subsequent workload has only 3 workers, the repartitioning mechanism will redistribute the partitions from 4 to 3, allowing the next workload to function as expected. Currently, the Vineyard operator supports repartitioning based on dask.
Initiating a Repartition Job¶
For workloads based on Dask, we provide several annotations and labels to help users utilize the repartitioning mechanism in the Vineyard operator. The following list contains all the labels and annotations we offer:
Dask Repartition Drivers Configurations
Name
Yaml Fields
Description
“scheduling.k8s.v6d.io/dask-scheduler”
annotations
The service of dask scheduler.
“scheduling.k8s.v6d.io/dask-worker-selector”
annotations
The label selector of dask worker pod.
“repartition.v6d.io/enabled”
labels
Enable the repartition.
“repartition.v6d.io/type”
labels
The type of repartition, at present, only support dask.
“scheduling.k8s.v6d.io/replicas”
labels
The replicas of the workload.
The following is a demo of repartition based on dask. At first, we create a dask cluster with 3 workers.
Note
Please make sure you have installed the vineyard operator and vineyardd before running the following yaml file.
# install dask scheduler and dask worker.
$ helm repo add dask https://helm.dask.org/
$ helm repo update
# the dask-worker's image is built with vineyard, please refer
# https://github.com/v6d-io/v6d/blob/main/k8s/test/e2e/repartition-demo/Dockerfile.dask-worker-with-vineyard.
$ cat <<EOF | helm install dask-cluster dask/dask --values -
scheduler:
image:
tag: "2022.8.1"
jupyter:
enabled: false
worker:
# worker numbers
replicas: 3
image:
repository: ghcr.io/v6d-io/v6d/dask-worker-with-vineyard
tag: latest
env:
- name: VINEYARD_IPC_SOCKET
value: /var/run/vineyard.sock
- name: VINEYARD_RPC_SOCKET
value: vineyardd-sample-rpc.vineyard-system:9600
mounts:
volumes:
- name: vineyard-sock
hostPath:
path: /var/run/vineyard-kubernetes/vineyard-system/vineyardd-sample
volumeMounts:
- mountPath: /var/run
name: vineyard-sock
EOF
Deploy the repartition workload1 as follows:
$ kubectl create namespace vineyard-job
$ cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: dask-repartition-job1
namespace: vineyard-job
spec:
selector:
matchLabels:
app: dask-repartition-job1
replicas: 1
template:
metadata:
annotations:
scheduling.k8s.v6d.io/dask-scheduler: "tcp://my-release-dask-scheduler.default:8786"
# use ',' to separate the different labels here
scheduling.k8s.v6d.io/dask-worker-selector: "app:dask,component:worker"
labels:
app: dask-repartition-job1
repartition.v6d.io/type: "dask"
scheduling.k8s.v6d.io/replicas: "1"
# this label represents the vineyardd's name that need to be used
scheduling.k8s.v6d.io/vineyardd-namespace: vineyard-system
scheduling.k8s.v6d.io/vineyardd: vineyardd-sample
scheduling.k8s.v6d.io/job: dask-repartition-job1
spec:
schedulerName: vineyard-scheduler
containers:
- name: dask-repartition-job1
image: ghcr.io/v6d-io/v6d/dask-repartition-job1
imagePullPolicy: IfNotPresent
env:
- name: JOB_NAME
value: dask-repartition-job1
- name: DASK_SCHEDULER
value: tcp://my-release-dask-scheduler.default:8786
volumeMounts:
- mountPath: /var/run
name: vineyard-sock
volumes:
- name: vineyard-sock
hostPath:
path: /var/run/vineyard-kubernetes/vineyard-system/vineyardd-sample
EOF
The first workload will create 4 partitions (each partition as a localobject):
$ kubectl get globalobjects -n vineyard-system
NAME ID NAME SIGNATURE TYPENAME
o001d2a6ae6c6e2e8 o001d2a6ae6c6e2e8 s001d2a6ae6c6d4f4 vineyard::GlobalDataFrame
$ kubectl get localobjects -n vineyard-system
NAME ID NAME SIGNATURE TYPENAME INSTANCE HOSTNAME
o001d2a6a6483ac44 o001d2a6a6483ac44 s001d2a6a6483a3ce vineyard::DataFrame 1 kind-worker3
o001d2a6a64a29cf4 o001d2a6a64a29cf4 s001d2a6a64a28f2e vineyard::DataFrame 0 kind-worker
o001d2a6a66709f20 o001d2a6a66709f20 s001d2a6a667092a2 vineyard::DataFrame 2 kind-worker2
o001d2a6ace0f6e30 o001d2a6ace0f6e30 s001d2a6ace0f65b8 vineyard::DataFrame 2 kind-worker2
Deploy the repartition workload2 as follows:
$ kubectl label namespace vineyard-job operation-injection=enabled
$ cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: dask-repartition-job2
namespace: vineyard-job
spec:
selector:
matchLabels:
app: dask-repartition-job2
replicas: 1
template:
metadata:
annotations:
scheduling.k8s.v6d.io/required: "dask-repartition-job1"
scheduling.k8s.v6d.io/dask-scheduler: "tcp://my-release-dask-scheduler.default:8786"
# use ',' to separate the different labels here
scheduling.k8s.v6d.io/dask-worker-selector: "app:dask,component:worker"
labels:
app: dask-repartition-job2
repartition.v6d.io/enabled: "true"
repartition.v6d.io/type: "dask"
scheduling.k8s.v6d.io/replicas: "1"
# this label represents the vineyardd's name that need to be used
scheduling.k8s.v6d.io/vineyardd-namespace: vineyard-system
scheduling.k8s.v6d.io/vineyardd: vineyardd-sample
scheduling.k8s.v6d.io/job: dask-repartition-job2
spec:
schedulerName: vineyard-scheduler
containers:
- name: dask-repartition-job2
image: ghcr.io/v6d-io/v6d/dask-repartition-job2
imagePullPolicy: IfNotPresent
env:
- name: JOB_NAME
value: dask-repartition-job2
- name: DASK_SCHEDULER
value: tcp://my-release-dask-scheduler.default:8786
- name: REQUIRED_JOB_NAME
value: dask-repartition-job1
envFrom:
- configMapRef:
name: dask-repartition-job1
volumeMounts:
- mountPath: /var/run
name: vineyard-sock
volumes:
- name: vineyard-sock
hostPath:
path: /var/run/vineyard-kubernetes/vineyard-system/vineyardd-sample
EOF
The second workload waits for the repartition operation to finish:
# check all workloads
$ kubectl get pod -n vineyard-job
NAME READY STATUS RESTARTS AGE
dask-repartition-job1-5dbfc54997-7kghk 1/1 Running 0 92s
dask-repartition-job2-bbf596bf4-cvrt2 0/1 Pending 0 49s
# check the repartition operation
$ kubectl get operation -A
NAMESPACE NAME OPERATION TYPE STATE
vineyard-job dask-repartition-job2-bbf596bf4-cvrt2 repartition dask
# check the job
$ kubectl get job -n vineyard-job
NAME COMPLETIONS DURATION AGE
repartition-o001d2a6ae6c6e2e8 0/1 8s 8s
After the repartition job finishes, the second workload will be scheduled:
# check all workloads
$ kubectl get pod -n vineyard-job
NAME READY STATUS RESTARTS AGE
dask-repartition-job1-5dbfc54997-7kghk 1/1 Running 0 5m43s
dask-repartition-job2-bbf596bf4-cvrt2 0/1 Pending 0 4m30s
repartition-o001d2a6ae6c6e2e8-79wcm 0/1 Completed 0 3m30s
# check the repartition operation
# as the second workload only has 1 replica, the repartition operation will repartitioned
# the global object into 1 partition
$ kubectl get globalobjects -n vineyard-system
NAME ID NAME SIGNATURE TYPENAME
o001d2ab523e3fbd0 o001d2ab523e3fbd0 s001d2ab523e3f0e6 vineyard::GlobalDataFrame
# the repartition operation will create a new local object(only 1 partition)
$ kubectl get localobjects -n vineyard-system
NAMESPACE NAME ID NAME SIGNATURE TYPENAME INSTANCE HOSTNAME
vineyard-system o001d2dc18d72a47e o001d2dc18d72a47e s001d2dc18d729ab6 vineyard::DataFrame 2 kind-worker2
The whole workflow can be found in dask repartition e2e test. What’s more, please refer the repartition directory to get more details.
Failover mechanism of vineyard cluster¶
If you want to back up data for the current vineyard cluster, you can create a Backup CR to perform a backup operation. As the Backup CR will use the default service account of the namespace the vineyard operator is deployed, you need to set up the same namespace as the vineyard operator. Please refer the Backup CRD for more details.
After data backup, you can create a Recover CR to restore a certain vineyard backup data. Please refer the Recover CRD for more details.
Next, we will show how to use the failover mechanism in vineyard operator. Assuming that we have a vineyard cluster that contains some objects, then we create a backup cr to back up the data. The following is the yaml file of the backup:
Note
Please make sure you have installed the vineyard operator and vineyardd before running the following yaml file.
$ cat <<EOF | kubectl apply -f -
apiVersion: k8s.v6d.io/v1alpha1
kind: Backup
metadata:
name: backup-sample
namespace: vineyard-system
spec:
vineyarddName: vineyardd-sample
vineyarddNamespace: vineyard-system
backupPath: /var/vineyard/dump
persistentVolumeSpec:
storageClassName: manual
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
hostPath:
path: /var/vineyard/dump
persistentVolumeClaimSpec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
EOF
Assuming that the vineyard cluster crashes at some point, we create Recover CR to
restore the data in the vineyard cluster, and the recover yaml file is as follows:
$ cat <<EOF | kubectl apply -f -
apiVersion: k8s.v6d.io/v1alpha1
kind: Recover
metadata:
name: recover-sample
namespace: vineyard-system
spec:
backupName: backup-sample
backupNamespace: vineyard-system
EOF
Then you could get the Recover’s status to get the mapping relationship between the object ID during backup and the object ID during recovery as follows:
$ kubectl get recover -A
NAMESPACE NAME MAPPING STATE
vineyard-system recover-sample {"o000ef92379fd8850":"o000ef9ea5189718d","o000ef9237a3a5432":"o000ef9eb5d26ad5e","o000ef97a8289973f":"o000ef9ed586ef1d3"} Succeed
If you want to get more details about the failover mechanism of vineyard cluster, please refer the failover e2e test.